

Search Disrupted Newsletter (Issue 11)
AI Switch Scam, Chrome Agentspace, Utility Problem, Human First AI Marketing, and BrowseComp
Google, OpenAI & Anthropic Model Switching Scandal: Are You Getting Scammed?
Berkeley researchers investigated if major API providers secretly use cheaper LLM alternatives while charging premium rates. Their findings show detection is surprisingly difficult:
- Text classifiers completely fail to distinguish between original and quantized models
- “What model are you?” prompts yield only vague responses about identity
- Statistical tests break down with just 20% randomized substitution
- Benchmark scores between original and quantized models are nearly identical
The SEO Black Box Gets Blacker
API providers actively restrict information about their models, making verification nearly impossible. This inability to audit providers creates an even bigger headache for SEOs struggling with AI-powered search transforming the landscape.
When providers obfuscate which models power their systems, SEOs can’t reliably:
- Predict how content will be processed and ranked
- Determine if quirky search behaviors are due to model substitution
- Create consistent optimization strategies across different AI surfaces
The trend toward less transparency - combined with the fracturing of search across multiple AI interfaces - means SEOs must now optimize for a moving target they can’t see.
Link: https://arxiv.org/pdf/2504.04715
Chrome + Google Agentspace
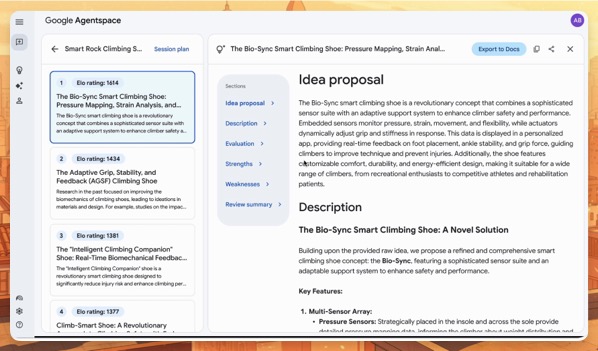
SEOs mostly don’t think about enterprise search (employees searching for information across their organization’s data) because why would they? However, in this case, Google is releasing enterprise search features that they will inevitably push to the consumer side.
Google just launched a major update to Agentspace, their enterprise AI platform, and some interesting changes exist.
First up, they’re bringing Agentspace search directly into Chrome’s search box. Something that we’re for sure going to see more of in the future (easy access to specialized search agents baked directly into the browser).
Second, the new Deep Research agent is a game changer as it pulls in data from both internal and external sources. This further cements the idea that the future of search will be optimizing for bots Googling on behalf of people.
Link: Google Agentspace Announcement
Utility Problem and AI halftime
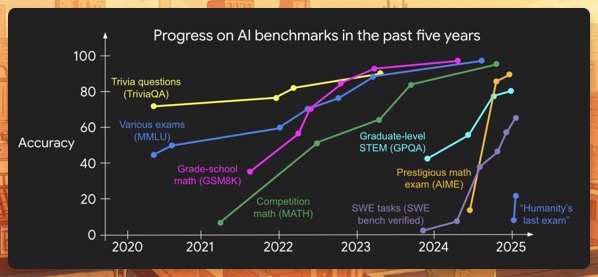
If AI models keep getting smarter, why do they still seem so dumb? Part of the answer is our shifting expectations, but there’s also a real utility problem.
Put another way, how we evaluate AI models differs from how we assess humans, and friction is the cause of a lot of the AI letdowns.
Shunyu Yao (OpenAI researcher) has a compelling post where he argues that we’re just now completing the first half of the initial AI wave and that we will see similar advances going forward, albeit achieved differently.
For SEOs in particular, this is an essential read as it highlights the mass changes we’re still likely to see over the next several years.
Link: The Second Half
Human First AI Marketing
I had a great talk with Mike Montague on the Human First AI Marketing podcast this week.
We discuss why the most important answers about your brand shouldn’t be hidden behind forms, how to publish content AI can actually read and recommend, and why challenger brands have more opportunity than ever to outsmart big players.
Link: Human First AI Marketing
BrowseComp - OpenAI’s New Benchmark
I’m generally very positive about the impact of AI on search, but if there’s one innovation that threatens the search market as we know it, it’s “Deep Research” agents.
We’re hurtling towards a future where people don’t see search results at all but just “reports” of search results. The new AI modes, deep research tools, and interfaces all clearly depict what this looks like.
To date, however, the tools to measure how good these tools are have been lacking, and it’s in this gap that OpenAI’s new BrowseComp benchmark is stepping in.
What makes BrowseComp particularly interesting is its design philosophy. The questions are intentionally difficult - human trainers verified that existing models (including GPT-4o with browsing capabilities) couldn’t solve them. They also confirmed that answers wouldn’t appear on the first page of search results and that even humans would struggle to find solutions within ten minutes.
Link: BrowseComp
Thanks this week
We did some live teardowns of sites’ AI search strategies and demoed the latest version of Knowatoa for a group of startups this week. Thanks to Kevin Miller from Ninja Proxy for being a guinea pig and letting us use his site for the event.


p.s. It would really help me out if you could Follow me on LinkedIn