

Search Disrupted Newsletter (Issue 38)
A new Knowatoa case study with TRMNL, Google Research on model memory, llms.txt is theater, and Claude's gains are ChatGPT's pains.
Case study: how we helped TRMNL accelerate with content
We published a new case study this week on our work with TRMNL, makers of the e-ink dashboards that broke pre-sales records with their recent TRMNL X launch.
In my professional life I’ve never received an SEO audit that didn’t feel underwhelming. Too often the audit and the content plan that follows are overly focused on the technical, not the business needs. As we’re all up to our eyeballs in AI right now, that technical analysis is still necessary but a lot less valuable. You can pull it out of any AI tool now.
What we did for TRMNL was take the technical as a starting point and then ask the harder questions:
- What are their customers actually trying to solve?
- Does the content meet that need?
- What terms are they searching for?
- How do they describe their problems?
From that we built a content strategy that crosses traditional search, AI search, social media, and conversion rate optimization, all focused on increasing sales.
And because I would sooner throw my MacBook out the window than deliver a zip file full of disconnected spreadsheets, docs, and slides as a “report.”
We delivered the output as an interactive web app that was searchable, comprehensive, and linked directly with their project management and AI production tools.
Link: How we helped TRMNL accelerate with content

Google Research: model memory is the filter on retrieval
A Google Research paper this week from Zorik Gekhman and Jonathan Herzig, titled “Thinking to recall,” shows that chain-of-thought reasoning unlocks knowledge already baked into the model’s weights, even on simple factual questions where there’s no actual reasoning to do.
This confirms what we’ve been saying. When a reasoning model answers a question about your category, it produces intermediate facts about adjacent companies and concepts on the way to the final answer. The brands that show up in those steps get pulled forward. The brands that don’t, don’t.
The underlying sentiment, and what the model already knows and considers about you, matters more than what happens on the retrieval side. Model memory is the filter that shapes what retrieval can surface in the first place. The robots.txt, sitemap, llms.txt theater is fighting for the margins.
Link: Thinking to recall: How reasoning unlocks parametric knowledge in LLMs
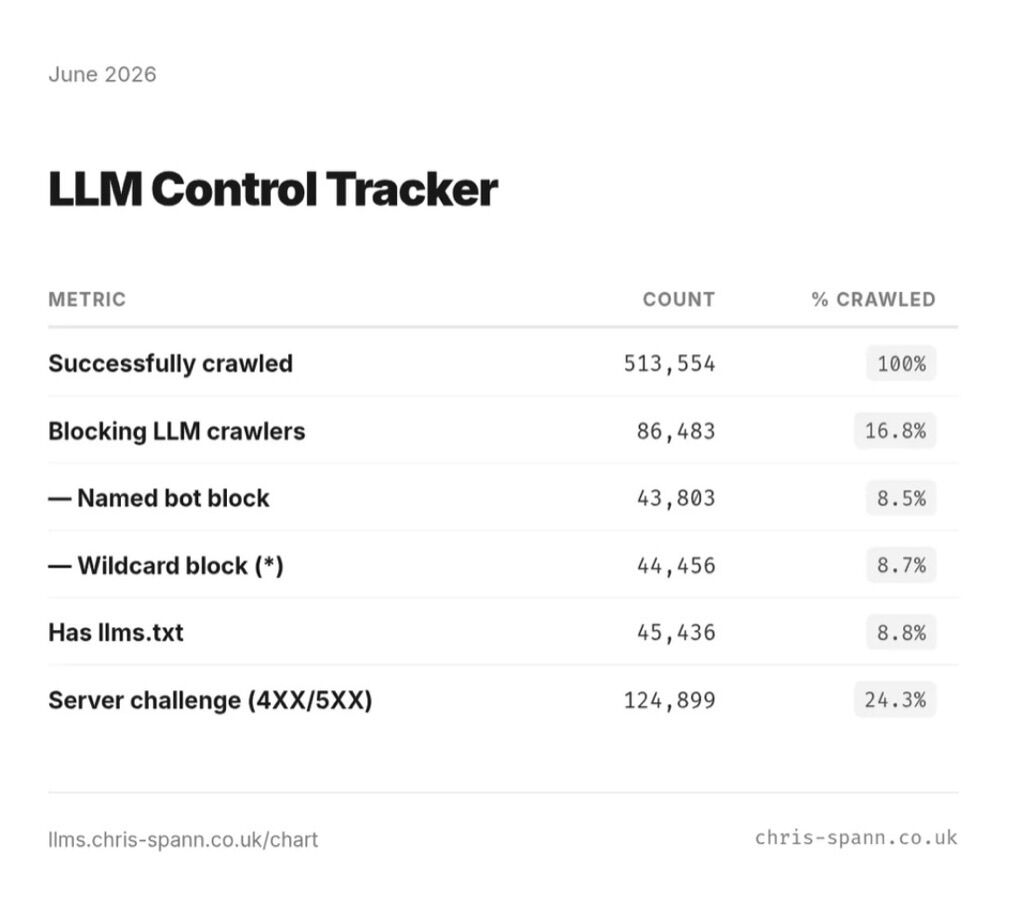
Two independent crawls, same conclusion: llms.txt is theater
A new report crawled a million sites this month to see how the web is actually responding to LLM crawlers:
- 16.8% of sites block one or more LLM crawlers
-
8.8% publish an
llms.txtfile -
24.3% return a 4XX or 5XX on
robots.txtitself
Pair that with a separate 300,000-domain study cited in r/SEO the same week, finding no measurable relationship between publishing llms.txt and getting cited by AI engines, and you have two independent crawls landing in the same place.
llms.txt is a proposal, not a standard, and no major AI engine has publicly committed to reading it. The 8.8% adoption rate is mostly conference-circuit influence.
The genuinely interesting number is the 24.3% of sites returning errors on robots.txt. That’s a quarter of the web shipping a broken instruction file to every crawler. Before you spend an afternoon hand-curating an llms.txt, make sure the file the crawlers actually read is returning a 200.
Link: I’m crawling 1M sites to see how they’re controlling LLMs or bothering with llms.txt
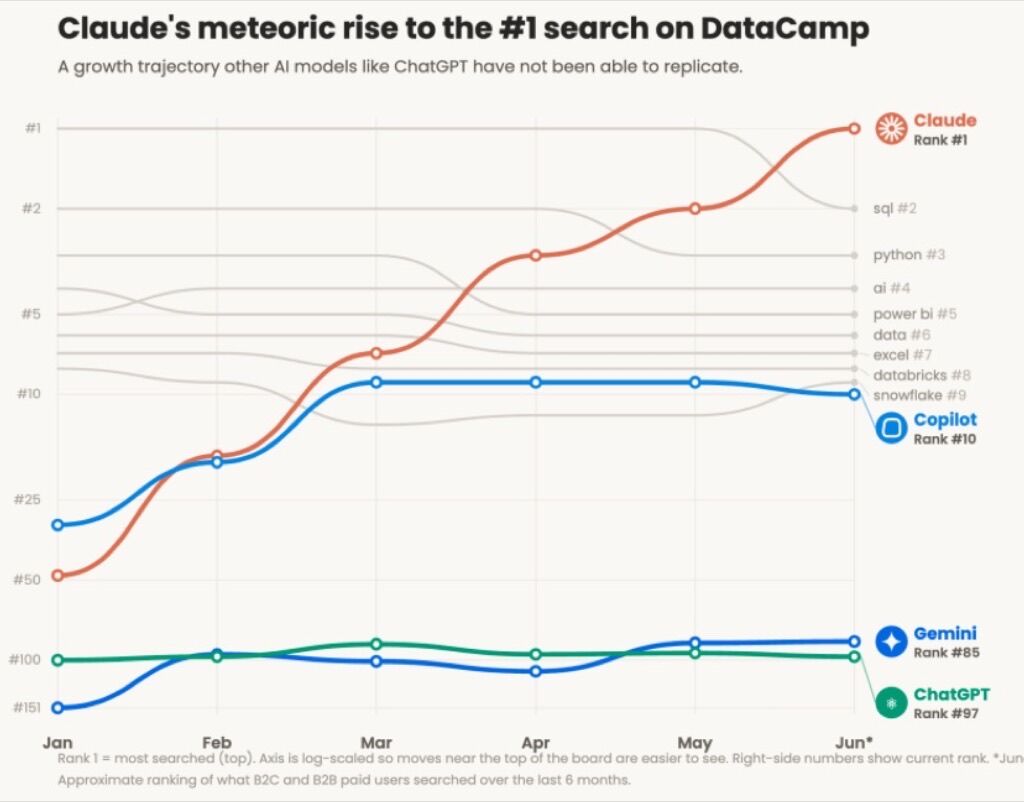
Claude’s gains are ChatGPT’s pains
TechCrunch reports Claude’s revenue from paying consumers is up roughly 75% since January 2026. DataCamp says demand for Claude courses jumped 18x in the last 30 days, Claude outpaces ChatGPT three to one among their learners, and “Claude” has overtaken “AI” as the most-searched term on the platform.
ChatGPT is still the bigger absolute number. But the Claude slice skews toward people who get paid to use these tools all day, the audience that matters for brand visibility. If your brand has been showing up in ChatGPT but you’ve never measured what Claude says about you, you have a blind spot in front of the highest-intent audience there is.
ChatGPT, Claude, Perplexity, Gemini, and Google’s AI products all generate different answers to the same prompt. You can check all of these at once with Knowatoa. Optimizing for one is optimizing for a fraction of the room.
Link: Anthropic’s Claude is winning over paid consumers, a market owned by ChatGPT
Thanks
Thanks again to TRMNL for being willing to share our work publicly via the case study.
Thanks for reading. These take real time to put together and the replies are what keep them going. Hit reply and tell me what you’re seeing on your dashboards.

