

Search Disrupted Newsletter (Issue 27)
Kagi declares war on AI slop, ChatGPT becomes a potential snitch, Google expands AI Mode globally, Reddit reputation attacks expose new risks, and Perplexity faces legal battles with Reddit and Amazon.
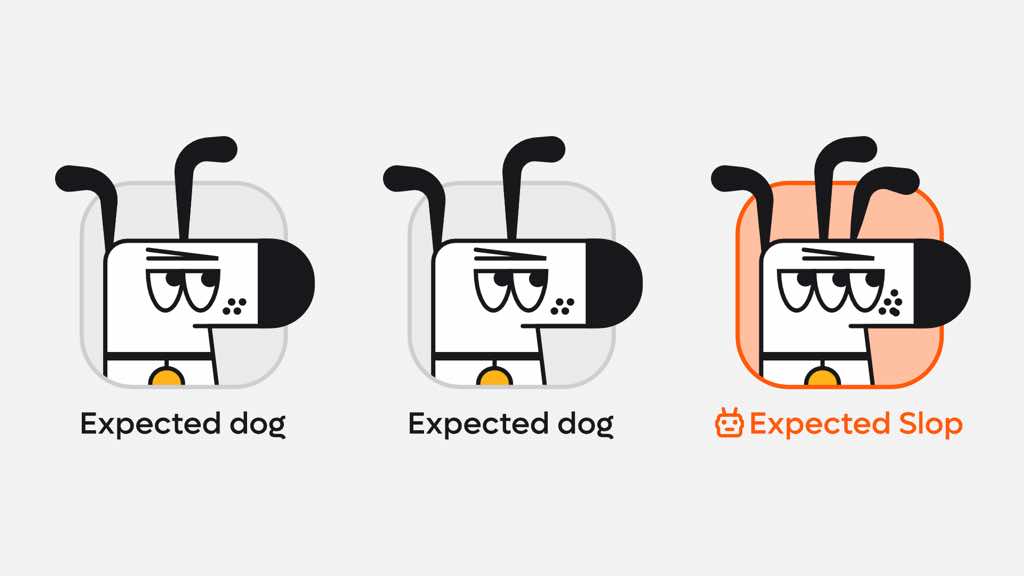
Kagi launches SlopStop to filter out AI-generated garbage
Kagi, a privacy-focused search engine, has launched SlopStop to filter out low-quality, AI-generated content.
This feature specifically targets useless content churned out to game search engines, which Kagi calls “expected dog” content, lacking real insight.
This mirrors similar actions from platforms like Pinterest, which now also has an AI filter option.
Kagi believes users will choose quality over quantity, a stance that contrasts with Google’s ad-driven approach.
Sidenote: Did you see the report that ~10% of Meta’s revenue is explicitly from scam advertisers?
For search marketers, SlopStop is a clear warning. Being filtered now extends beyond traditional SEO mistakes to include generic AI fluff that lacks value.
While I applaud the effort, given how fast AI is improving, it’s hard not to think that the ability to identify AI-generated content algorithmically is a temporary state of things.
Link: Kagi SlopStop
ChatGPT is a Narc
The Future of Being Human highlights how ChatGPT is being increasingly used to report users to authorities.
People discussing sensitive or illegal topics may find their conversations reported, blurring the line between helpful AI and digital surveillance.
My big concern is that OpenAI hasn’t clarified when or on what topics ChatGPT will actually take action.
While any initiatives to stop things like CSAM and self-harm are commendable, it still feels disquieting not to have any guidelines.
We’re clearly seeing users share much more intimate details of their lives with AI, and I wonder how much they’ll reconsider if this becomes more widespread.
Link: When ChatGPT Turns Snitch

Google expands AI Mode globally
Google just launched AI Mode in Hindi, Indonesian, Japanese, Korean, and Portuguese, marking its first expansion beyond English.
AI overviews have been global for a while (with billions of users), but this feels more like a genuine shift.
Given how adept LLMs are at language translation, I wonder if this will make content more accessible and broadly available.
For years, non-English search markets have seen less competition simply because there were fewer sites in those languages; however, I suspect that’s changing with LLMs (and AI Mode in particular), which can handle translations on the fly.
Link: Google Expands AI Mode to New Languages

Reddit reputation attacks just became a real business threat
Lars Lofgren detailed a sophisticated Reddit attack targeting Codesmith, a coding boot camp.
The attack featured: - Multiple Reddit accounts posting coordinated negative reviews - Strategic upvoting to gain visibility - Timed posts to maximize reach - Biased moderators (a persistent Reddit problem).
This type of attack is now more dangerous, as Reddit content has become so prominent in both traditional and AI search results.
You might have near-perfect reviews on Google, Yelp, and Trustpilot, and a stray Reddit comment can still break through.
The only defense is proactive community engagement and a strong presence on Reddit before an attack or wave of negativity hits.
Link: Reddit Reputation Attack Case Study

Google’s Speech-to-Retrieval might finally make voice search work
Google Research unveiled Speech-to-Retrieval (S2R), a new approach that could finally make voice search a faster and more accurate search mode.
How it works: - Traditional voice search: speech → text → search (breaks if transcription is wrong) - S2R: speech → semantic meaning → match (works even with transcription errors)
This solves a decade-long problem. Say “Knowatoa,” and even if it hears “no a toe uh,” the semantic meaning still matches correctly.
I’m personally using voice-to-text constantly (literally right now) as I suffer from pretty bad RSI issues in my hands. And while the state of the art has improved dramatically with tools like Macwhisper and Superwhisper, it’s still not quite there.
Having something like S2R that would make this even better would be amazing.
There was a decade-long transition from desktop to mobile search, and we are now seeing an even faster transition from typed search to voice search.
Link: Google Speech-to-Retrieval Research

Amazon tells Perplexity to stop its shopping agent
Amazon has ordered Perplexity to halt its AI shopping agent, which was making unauthorized purchases on the Amazon platform.
Perplexity’s agent allowed users to request purchases, such as “buy the best noise-canceling headphones,” and then researched and purchased items on Amazon.
Amazon states Perplexity’s bot violated its Terms of Service by automating purchases and, crucially, bypassed Amazon’s entire recommendation and advertising system, which makes them just absolutely stupid amounts of high-margin revenue.
Revenue that would be lost if AI agents from Google, Perplexity, and ChatGPT could jump forward and treat Amazon like a fulfillment service.
This marks Perplexity’s second major legal challenge this week, highlighting conflicts that arise from AI systems operating at a rapid pace. Move fast and be sure to have your lawyers on speed dial, I guess.
Search is indisputably getting more “Agentic”, as every day more people choose to have an AI filter through their search results for them (either via ChatGPT + search) or explicitly through things like AI mode or Deep research tools.
Link: Amazon Demands Perplexity Stop AI Shopping

The IRS just open-sourced a fact-checking graph database
The IRS released Fact Graph, an open-source knowledge graph database designed for fact-checking. It structures facts, sources, connections, and verification status to confirm claims automatically.
Developed to combat tax scams and misinformation, Fact Graph signals a broader need for scalable, organized fact-checking in the age of abundant AI-generated content.
I’ve been skeptical of the efficacy of AI-specific data publishing formats, such as LLMs.txt, etc. But I do think that publishing a clear set of “facts” about your company to GitHub feels like a can’t-miss win on the content side.
Link: IRS Fact Graph on GitHub

Wikimedia reports AI is hurting traffic
Wikimedia data shows that AI overviews and chatbot summaries are significantly reducing Wikipedia’s traffic, which is a bummer for their fundraising efforts, a usability win for actual users, and a stark warning for publishers.
Why this matters: - Wikipedia is useful, non-commercial, and relied upon by everyone. The absolute top tier of “informational” search. - If AI hurts Wikipedia’s traffic, what does this signal for the low-intent and high-traffic posts on your site? - Zero-click search means users get answers without visiting source pages
For publishers and content marketers, the old business model is breaking. “Create content, get traffic, monetize attention” no longer works when AI provides direct answers.
Brands that succeed will build value and drive results deeper in the funnel even when AI systems answer questions without sending traffic.
Link: Wikimedia on AI Traffic Impact

Reddit sues Perplexity for unauthorized scraping
Reddit is suing Perplexity and three other companies for scraping content without permission or payment.
The legal arguments: - Reddit: We license content to Google and OpenAI. Perplexity is using it without a license. - Perplexity (likely): This is fair use, just like Google indexing the web, and hey, maybe we’re also getting it from the Internet Archive.
This is purely a financial issue.
I’ve seen some people arguing that Google sends traffic back to sources, and Perplexity doesn’t (to a degree), but honestly, looking at AI Mode and AI Overviews, I think that argument falls apart.
For search marketers, this lawsuit asks a fundamental question: Can AI companies index and summarize your content without permission?
If Reddit wins: AI search companies must license content from major platforms, slowing growth.
If Perplexity wins: AI indexing is fair use, and content creators have limited control.
We’re going to be seeing versions of this case for years.
Link: Reddit Sues Perplexity

Product Updates
We’ve been busy building new features at Knowatoa. In the last few weeks, we rolled out 9 big updates. They’re all designed to help you track and improve how visible you are in AI search. Here’s what’s new:
Research Hub Suggested Questions - AI-powered question discovery from recent conversations. Stop guessing what to track.
Sign In with Google - One-click sign up and login. No more passwords or email verification.
Deep Dive into Individual Questions - Dedicated pages for each question showing how ChatGPT, Perplexity, Claude, and Gemini each respond.
Track Changes Over Time - Filter competitor visibility, sentiment, and sources by time period to see if your optimization is working.
Domain Classification - Citations grouped by domain with News, Social, Reference, and E-commerce categories.
Keyword Analysis - Comprehensive breakdown of your questions by intent, category, and funnel stage.
CSV Exports for All Plans - Your data, your way. Export everything regardless of your subscription tier.
Faster Site Setup - AI-generated competitors and questions get you tracking faster.
AI Search Console Refresh - Better presentation and clearer explanations for first-time visitors.
Thanks for your patience
This is the longest I’ve gone between newsletters all year (almost a month), and I’ve really missed sending these out, as I always receive such nice replies.


p.s. It would really help me out if you could Follow me on LinkedIn